【论文笔记】Prefix-Tuning+: Modernizing Prefix-Tuning through Attention Independent Prefix Data
Title: Prefix-Tuning+: Modernizing Prefix-Tuning through Attention Independent Prefix Data
Authors: Haonan Wang, Brian K. Chen, Siquan Li, Xinhe Liang, Hwee Kuan Lee, Kenji Kawaguchi, Tianyang Hu
Affiliations: National University of Singapore; Bioinformatics Institute, A*STAR; Nanyang Technological University; Singapore Eye Research Institute; Singapore International Research Laboratory on AI; Singapore Institute for Clinical Sciences.
Conference: ICML 2025
一、研究背景与动机
- Prefix-Tuning:是一种经典的 PEFT 方法:在输入序列前添加可学习的“前缀”,通过影响注意力机制来引导模型生成。
- 但作者发现,在当前主流的大型语言模型(LLM)上,标准 Prefix-Tuning 的效果远不如 LoRA。
- 核心问题:不是前缀长度或初始化问题,而是一个架构级别的缺陷———前缀与真实输入在注意力头内部存在冲突。
二、问题诊断
| 现象 | 原因 |
|---|---|
| 前缀过长 | 模型过度关注前缀,忽略输入内容 |
| 输入过长 | 前缀影响被稀释 |
| 本质 | 注意力机制中,前缀与真实输入共享注意力分数,导致此消彼长 |
前缀应当影响模型行为,但不应该与输入内容“争夺”注意力权重。
核心方法:Prefix Tuning+(PMT)
该方法的具体名称经历了由PT+改为PMT(PrefixMemotyTuning),在此笔者最终决定统一表述为PMT
设计思想
将前缀从注意力头内部解耦出来,不再参与注意力权重的竞争。
如何实现?
- 引入一个独立于注意力机制的外部模块
- 该模块由一个可训练的矩阵和表示函数组成
- 不改变原始注意力计算流程,而是并行地影响表示
形式上可以理解为:前缀不再挤占输入的位置,而是作为一种独立的控制信号。
与传统Prefix Tuning的区别
| Prefix-Tuning | PMT | |
|---|---|---|
| 前缀作用方式 | 与输入拼接,参与注意力计算 | 独立于注意力,不参与权重竞争 |
| 与输入的交互 | 竞争注意力权重 | 无直接竞争 |
| 对长输入的适应性 | 差 | 好 |
四、实验设置与结果
任务类型
- 少量样本学习(few-shot)
- 多个NLU和NLG基准任务
方法
- 全参数微调
- Prefix-Tuning
- LoRA
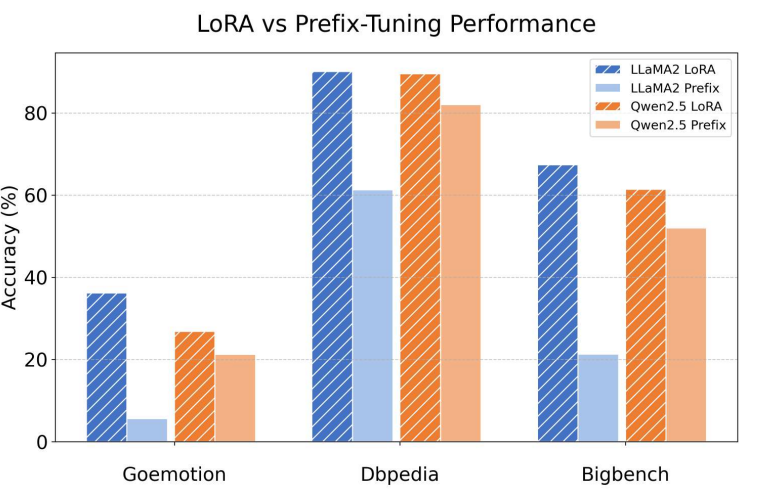
实验结果
| 方法 | 相对LoRA的表现 |
|---|---|
| Prefix Tuning | 显著落后 |
| Prefix Tuning | 平均提升 8.1%(优于 LoRA) |
| 相比 Prefix-Tuning | 提升 29.4% |
结论:
- PMT(PT+) 不仅修复了 Prefix-Tuning 的缺陷,还达到了与 LoRA 相当甚至更优的性能。
- 证明了“前缀式方法”在现代化改造后仍然具有竞争力。
五、贡献与总结
问题诊断:首次明确指出 Prefix-Tuning 在现代 LLM 上失效的根本原因是注意力内部的“零和博弈”。
方法创新:提出 PT+,通过注意力独立的前缀机制彻底解决该问题。
实验验证:在多个任务上显著超越原版 Prefix-Tuning,并达到与 LoRA 相当或更好的效果。
方法论启发:提醒研究者重新审视经典 PEFT 方法在新架构下的适用性。
The Future
- PEFT 的设计空间仍未穷尽:LoRA 虽强,但 Prefix-Tuning+ 说明前缀式方法仍有潜力可挖。
- 解耦是一个非常值得关注的思路:本文提出了将前缀从注意力竞争中解放出来,这种思路是否可以用到其他类似的“共享机制”策略的改进?
- 根据实际去做选型参考:当任务中输入长度变化大或者前缀过长,需进行计算开销来选取PMT还是LoRA